原文链接:https://cameronrwolfe.substack.com/p/llm-scaling-laws
模型的Scaling Law是OpenAI在2020年提出的概念[1],具体如下:
- 对于Decoder-only的模型,计算量C(Flops), 模型参数量N, 数据大小D(token数),三者满足: C≈6ND 。(推导见本文最后)
- 模型的最终性能主要与计算量C,模型参数量N和数据大小D三者相关,而与模型的具体结构(层数/深度/宽度)基本无关。
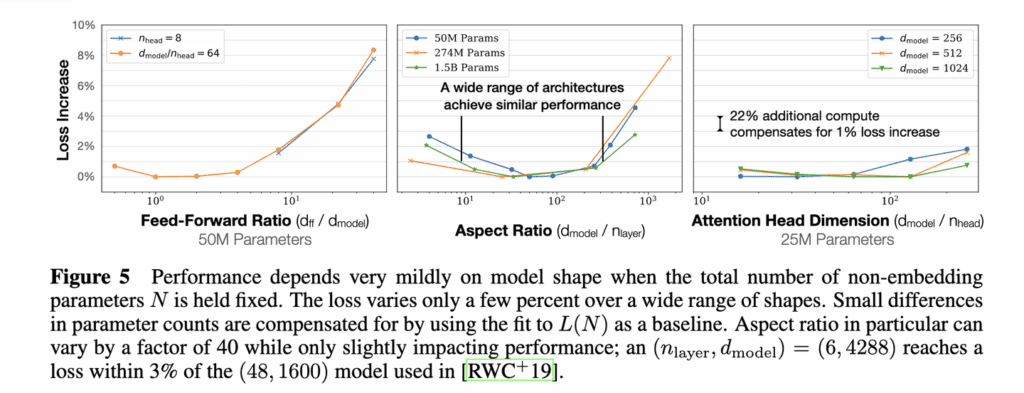
固定模型的总参数量,调整层数/深度/宽度,不同模型的性能差距很小,大部分在2%以内
3. 对于计算量C,模型参数量N和数据大小D,当不受其他两个因素制约时,模型性能与每个因素都呈现幂律关系
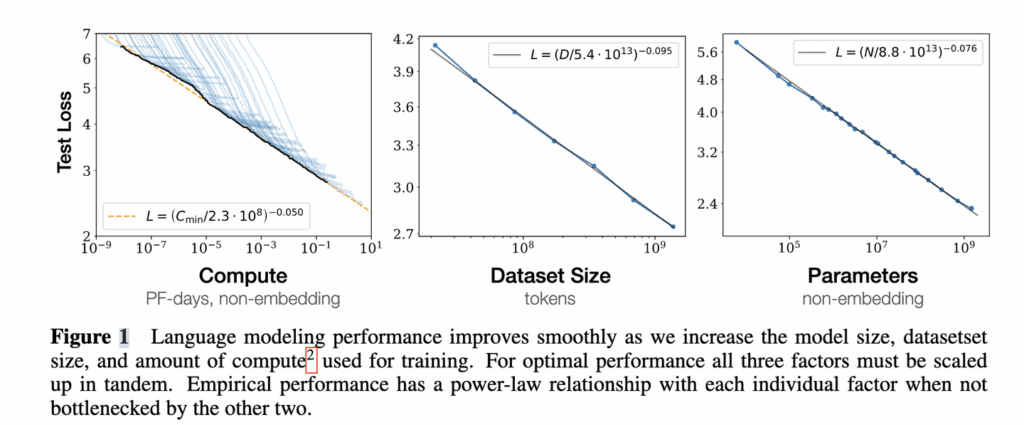
4. 为了提升模型性能,模型参数量N和数据大小D需要同步放大,但模型和数据分别放大的比例还存在争议。
5. Scaling Law不仅适用于语言模型,还适用于其他模态以及跨模态的任务[4]:
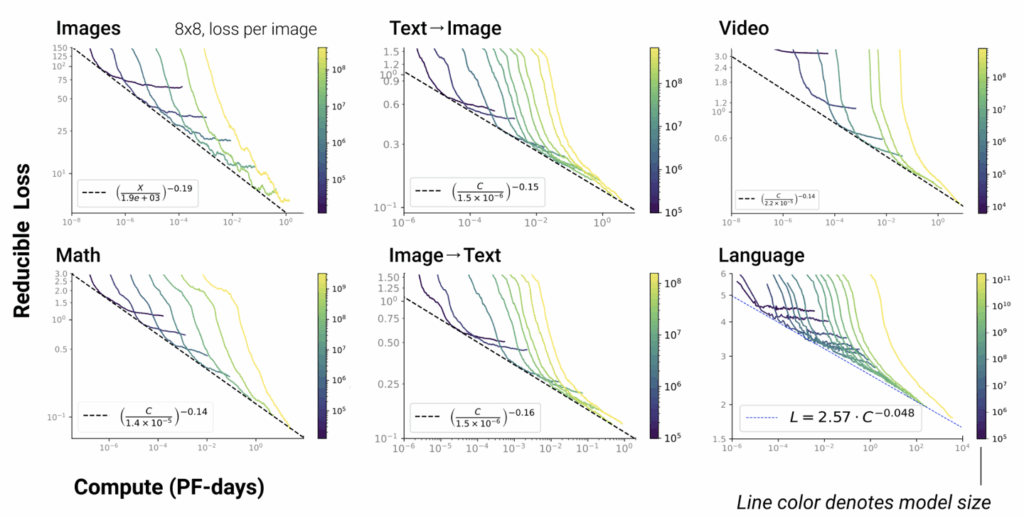
这里横轴单位为PF-days: 如果每秒钟可进行1015次运算,就是1 peta flops,那么一天的运算就是1015×24×3600=8.64×1019,这个算力消耗被称为1个petaflop/s-day。